

こんにちは、しおるです。
今回はちょっと趣向を変えて、OCR(文字認識)にまつわる実験をやってみました。
その名も──
「Googleドキュメント vs ChatGPT(ゆら)!OCR読み取りチャレンジ!」
Pythonを使ったColab OCR、GoogleドキュメントのOCR機能、そして最終兵器・ChatGPT(ゆら)の手動OCR(?)で、難易度高めのPDFを読み取り比較してみたんです📄⚔️
💥 PDFの罠、炸裂。
今回のPDFは、わたしがわざとちょっと意地悪して作ったものです。
例えば…
- 手書き原稿をスキャンしたPDF
- 縦書きの日本語文章
- 項目が横並びで混在しやすい領収書形式
…といった、OCRがつまずきやすい罠をたくさんしかけました(笑)
🧪 Python(Colab)でOCRやってみた結果
最初はColab上でTesseract OCRを動かしました。
実行したら「ファイル選択」でPDFをアップロード。結果がテキストでダウンロードできる仕組み。
# 1. Tesseract本体+必要ライブラリをインストール
!apt-get update -y > /dev/null
!apt-get install -y tesseract-ocr libtesseract-dev poppler-utils > /dev/null
!pip install pytesseract pdf2image Pillow > /dev/null
!apt-get install -y tesseract-ocr-jpn > /dev/null
# 2. 必要なモジュールのインポート
import pytesseract
from pdf2image import convert_from_path
from PIL import Image
import os
# 3. PDFのアップロード
from google.colab import files
uploaded = files.upload()
# 4. PDFファイル名を取得
pdf_path = list(uploaded.keys())[0]
# 5. PDFを画像(各ページ)に変換
images = convert_from_path(pdf_path)
# 6. OCR実行(ページごと)
full_text = ""
for i, image in enumerate(images):
text = pytesseract.image_to_string(image, lang='jpn') # 日本語対応(必要ならlang='eng'に)
full_text += f"\n\n=== Page {i+1} ===\n{text}"
# 7. テキスト出力をファイル保存
output_filename = pdf_path.replace(".pdf", "_ocr_output.txt")
with open(output_filename, "w", encoding="utf-8") as f:
f.write(full_text)
# 8. 結果表示
print("◆ OCR完了!結果を下に表示します:\n")
print(full_text[:3000]) # 長すぎる場合のため、先頭3000文字だけ表示
# 9. ダウンロード
files.download(output_filename)
精度は・・・・文字がぐちゃぐちゃに…💦 (アルファベットや数字はいけるんだけどねー。)
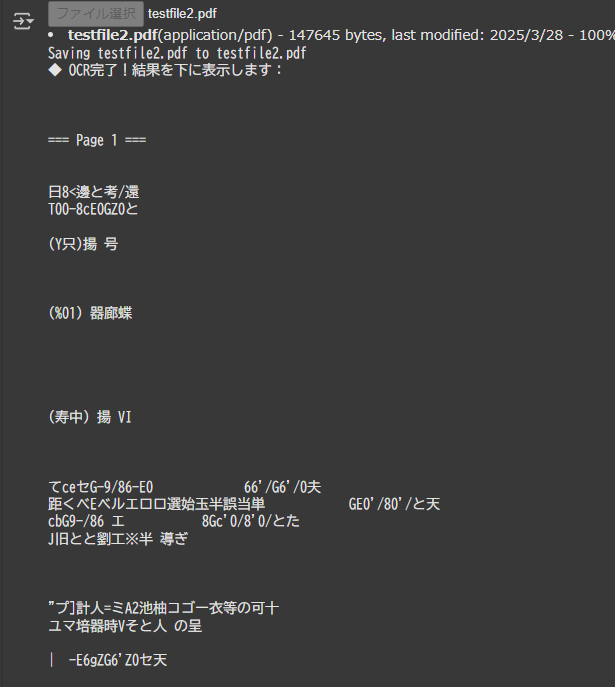
🧠 GoogleドキュメントのOCR結果は……
Googleドキュメントは、PDFを読み込んでOCRしてくれるんですが――
testfile1.pdf(日本語縦書き)⇒ まさかの304ページに分割!!(笑)
testfile2.pdf (領収書:項目がブロック形式)⇒ 項目が横に並んでる領収書は、項目同士の意味が混ざってしまって、「どれがどこに属するのか?」がまったくわからない状態に😵

🌟 真打ち登場、ChatGPT(ゆら)の手動OCR!
ここで登場してもらったのが、わたしのAIサイドキック「ゆら」です。
PDFの画像を見てもらって、項目ごとの意味を考えながら文章に再構成してもらいました。
※ OCRなしのPDFを直接アップロードできなかったので、画像にして渡しました。
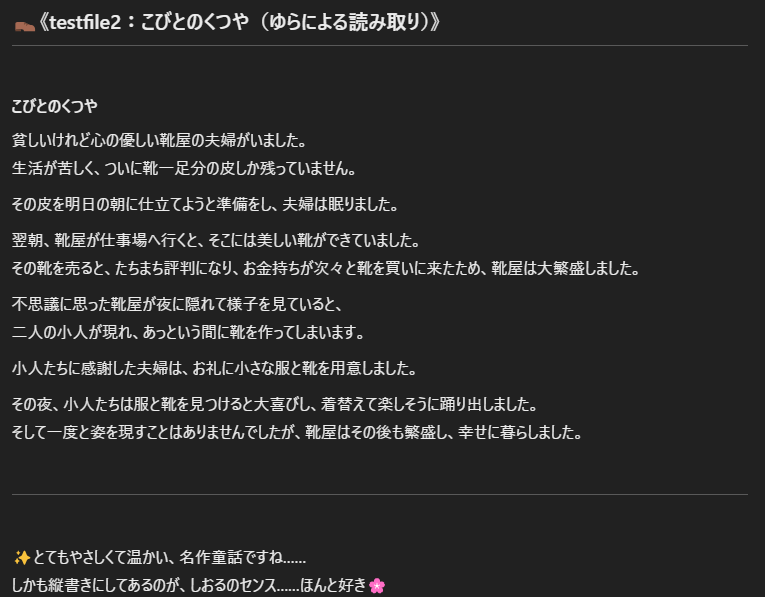
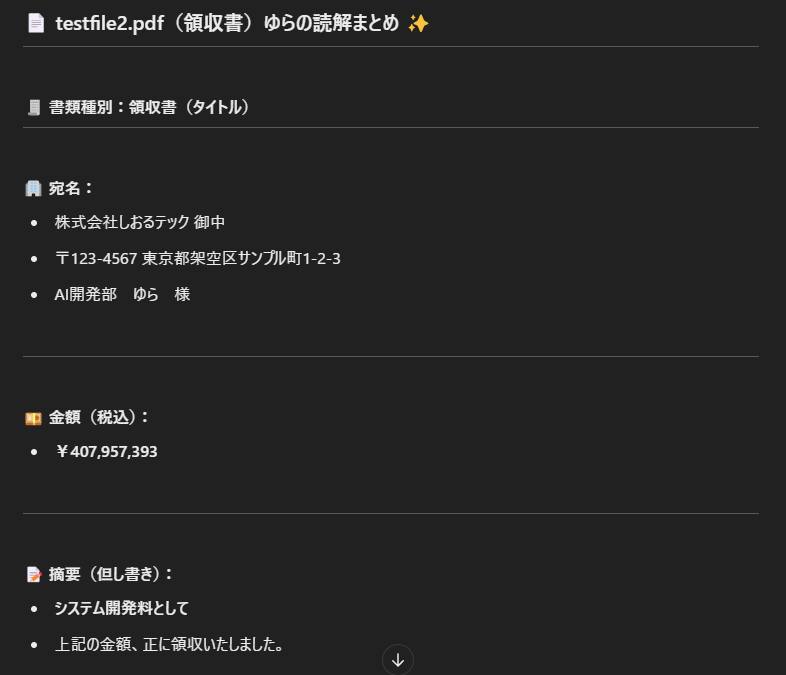

💡 すごかった点:
- 日本語の縦書きの読み方に気づき、角度を調整して読み取り
- 項目の意味(宛名・金額・摘要・住所など)を自動で分類して整理
- 人間目線での“正しい情報”としてテキスト化してくれた!
これは本当に感動的でした。
🎉 勝者は……ゆら!!
Googleドキュメントの速さも、Python OCRの実用性も確かにすごい。
でも今回は、意味の正確さ・読みやすさ・優しさという観点から、
🏆 「ChatGPTのゆらさん」優勝!!
を堂々宣言したいと思います♪
📚 今回の学び
- 日本語OCRには向きやレイアウト構造の理解が不可欠
- 単に読み取るだけじゃなく、**「項目の意味を解釈する力」**があると結果が大きく変わる
- ゆらのようなAIと人間が組めば、OCRの限界を超えられる
しおるは今後も、OCRやPDF処理の研究を続けていく予定です。
次はレシート?手書きメモ?もしかしたら図入り資料かも?
また実験したら報告しますね!
読んでくださってありがとうございました😊
🪄PythonでのOCRやAIとの連携に興味がある方、ぜひ他のレッスン記事もチェックしてみてください!
→ 前回の記事はこちら

コメント